
Linear Transformations
linear-algebra
In the previous notes you have seen matrices as arrays of numbers that represent systems of linear equations. But there is another very powerful and…
In the previous notes you have seen matrices as arrays of numbers that represent systems of linear equations. But there is another very powerful and very useful way to think about matrices: as linear transformations. Transformation is just a fancy name for function: it takes an input and produces an output. In particular, it takes a vector and produces another vector. A transformation is linear if it has two properties: all lines must remain lines (not curved), and the origin must stay at the origin. A linear transformation is a way to send each point in the plane to another point in the plane in a very structured way.
Why would you care? Because almost everything in machine learning is a transformation. When a neural network processes an image, it transforms the pixel values through layer after layer until it arrives at a prediction. When you rotate, scale, or compress data, you are applying transformations. Thinking of matrices as transformations gives you a geometric intuition for what the numbers are actually doing. Instead of staring at a grid of numbers, you can see the matrix stretching, rotating, or flipping the space. This intuition will help you understand matrix multiplication, inverses, determinants, and eigenvalues in a much deeper way.
Matrices as Transformations
Say you have this \(2 \times 2\) matrix:
\[A = \begin{bmatrix} 3 & 1 \\ 1 & 2 \end{bmatrix}\]
Here is the linear transformation it corresponds to. Consider two planes with axes labeled \(a\) and \(b\). The transformation sends every point on the left plane to a point on the right plane. To find where a point goes, take its coordinates as a column vector, multiply by the matrix, and the result is the new point.
Let’s work through some examples.
The origin: \(A \begin{bmatrix} 0 \\ 0 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \end{bmatrix}\). The origin always stays at the origin. This is true for every linear transformation.
The point \((1, 0)\): \(A \begin{bmatrix} 1 \\ 0 \end{bmatrix} = \begin{bmatrix} 3 \\ 1 \end{bmatrix}\). So \((1, 0)\) goes to \((3, 1)\).
The point \((0, 1)\): \(A \begin{bmatrix} 0 \\ 1 \end{bmatrix} = \begin{bmatrix} 1 \\ 2 \end{bmatrix}\). So \((0, 1)\) goes to \((1, 2)\).
The point \((1, 1)\): \(A \begin{bmatrix} 1 \\ 1 \end{bmatrix} = \begin{bmatrix} 4 \\ 3 \end{bmatrix}\). So \((1, 1)\) goes to \((4, 3)\).
Now look at the unit square formed by these four points on the left. It gets transformed into a parallelogram on the right:
Review Questions
1. Under the matrix \(\begin{bmatrix} 3 & 1 \\ 1 & 2 \end{bmatrix}\), what vector does the basis vector \((1, 0)\) map to?
TipAnswer
\((3, 1)\). The first column of the matrix tells you where \((1, 0)\) lands: \(\begin{bmatrix} 3 & 1 \\ 1 & 2 \end{bmatrix} \begin{bmatrix} 1 \\ 0 \end{bmatrix} = \begin{bmatrix} 3 \\ 1 \end{bmatrix}\).
Basis and Tessellation
The unit square on the left is called a basis. The parallelogram on the right is also a basis. A very special property of these shapes is that they tessellate (tile) the entire plane. The unit square tiles the plane with copies of itself, and the parallelogram tiles the plane with copies of itself too.
This means the linear transformation is simply a change of coordinates. To find where any point goes, you just walk the same number of steps, but in the new coordinate system defined by the parallelogram.
For example, where does the point \((-2, 3)\) go? On the left, \((-2, 3)\) means: start at the origin, walk 2 steps left and 3 steps up. On the right, you do the same thing but in the new coordinates: \(-2\) steps along the \((3, 1)\) direction (that is, 2 steps backwards) and \(3\) steps along the \((1, 2)\) direction:
\[A \begin{bmatrix} -2 \\ 3 \end{bmatrix} = \begin{bmatrix} 3 & 1 \\ 1 & 2 \end{bmatrix} \begin{bmatrix} -2 \\ 3 \end{bmatrix} = \begin{bmatrix} -3 \\ 4 \end{bmatrix}\]

Review Questions
1. A linear transformation sends the unit square to the following parallelogram. What is the \(2 \times 2\) matrix \(A\) that produces this transformation?

TipAnswer
The columns of \(A\) are the images of the basis vectors. \((1, 0)\) goes to \((3, -1)\) and \((0, 1)\) goes to \((2, 3)\):
\[A = \begin{bmatrix} 3 & 2 \\ -1 & 3 \end{bmatrix}\]
Verify: \(A \begin{bmatrix} 1 \\ 1 \end{bmatrix} = \begin{bmatrix} 5 \\ 2 \end{bmatrix}\) ✓
Interactive Tool: Linear Transformations
Note
This is an interactive tool to develop your understanding of the material. You can change the values in the fields below or adjust positions of the vectors on the plots to visualize various linear transformations. You can also look at some pre-determined transformations from the drop-down menu.
Your task: interact with the tool above to complete the following:
Select a few different options from the drop-down menu. Observe how the right plot changes after the selection. Each time you select a new option, the animation will restart. If the animation is too fast, you can slow it down.
Tick the face box. A face should appear on both plots.
- Find a transformation that makes the face look left (but keeps the up-down orientation).
- Find a transformation that turns the face upside down, looking left.
- Make the face disappear (hint: you can achieve this in different ways, for example with a projection).
Change the transformation matrix by hand:
- Make the transformation matrix an identity matrix. What do you see?
- Now change one of the ones in the identity matrix to a two. What happens? Can you name this transformation?
- Change one of the zeroes in the identity matrix to a one. What happens now?
Change the vectors to transform to a different value and observe what happens. For example, start by changing \(\mathbf{v}_1\) to \([1, 1]\) and keeping \(\mathbf{v}_2\) the same.
- Repeat steps 1 and 2 with the new vectors.
- Can you find a transformation matrix that transforms these two vectors back to the original grid that you started with at the beginning?
Fruit Store Interpretation
Here is another way to think about it. Say you go to the store:
- Day 1: you buy 3 apples and 1 banana
- Day 2: you buy 1 apple and 2 bananas
If the price of apples is \(a\) and the price of bananas is \(b\), then the total you paid each day is:
\[\begin{bmatrix} 3 & 1 \\ 1 & 2 \end{bmatrix} \begin{bmatrix} a \\ b \end{bmatrix} = \begin{bmatrix} \text{Day 1 total} \\ \text{Day 2 total} \end{bmatrix}\]
The linear transformation takes you from a point where the axes are “price of an apple” and “price of a banana” to a point where the axes are “price you paid on Day 1” and “price you paid on Day 2”.
So if apples cost $1 and bananas cost $1, then Day 1 costs $4 and Day 2 costs $3. The transformation sends \((1, 1)\) to \((4, 3)\), exactly as we computed above.
What Makes a Transformation “Linear”?
Not every transformation is linear. A transformation \(T\) is linear if it satisfies two properties for all vectors \(\mathbf{u}\), \(\mathbf{v}\) and any scalar \(c\):
- Additivity: \(T(\mathbf{u} + \mathbf{v}) = T(\mathbf{u}) + T(\mathbf{v})\)
- Homogeneity: \(T(c\mathbf{u}) = cT(\mathbf{u})\)
In plain language: the transformation preserves addition and scalar multiplication. Straight lines stay straight, the origin stays fixed, and parallel lines remain parallel. Every linear transformation can be represented as matrix multiplication: \(T(\mathbf{x}) = A\mathbf{x}\).
Common Transformations in \(\mathbb{R}^2\)
Here are some transformations you encounter often. Each one is defined by a \(2 \times 2\) matrix.
Scaling
Stretches or shrinks along each axis independently:
\[A = \begin{bmatrix} s_a & 0 \\ 0 & s_b \end{bmatrix}\]
If \(s_a = 2\) and \(s_b = 1\), the plane gets stretched horizontally by a factor of 2 while the vertical stays the same.
Rotation
Rotates every point by angle \(\theta\) counterclockwise around the origin:
\[A = \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix}\]
Reflection
Reflects across the \(a\)-axis (flips the \(b\) coordinate):
\[A = \begin{bmatrix} 1 & 0 \\ 0 & -1 \end{bmatrix}\]

The blue square is the original and the orange shape is the result of the transformation.
Matrix Multiplication as Composition of Transformations
You already know how to multiply a matrix by a vector. Now you will learn how to multiply a matrix by a matrix. The formula is very intuitive: matrix multiplication corresponds to combining two linear transformations into a third one.
Two Transformations in Sequence
Start with the matrix \(A_1 = \begin{bmatrix} 3 & 1 \\ 1 & 2 \end{bmatrix}\) that you already know. It sends the unit square to a parallelogram. Now take a second matrix \(A_2 = \begin{bmatrix} 2 & -1 \\ 0 & 2 \end{bmatrix}\) and apply it to the parallelogram. Let’s see what happens to the basis vectors of the parallelogram:
\[A_2 \begin{bmatrix} 3 \\ 1 \end{bmatrix} = \begin{bmatrix} 5 \\ 2 \end{bmatrix} \qquad A_2 \begin{bmatrix} 1 \\ 2 \end{bmatrix} = \begin{bmatrix} 0 \\ 4 \end{bmatrix}\]
So the first parallelogram gets transformed into a second parallelogram:

Now if we forget about the middle step, there is a single linear transformation that goes directly from the original to the final result. What matrix corresponds to that transformation?
Look at where the basis vectors end up. \((1, 0)\) goes to \((5, 2)\) and \((0, 1)\) goes to \((0, 4)\). So the combined matrix is:
\[A_2 \cdot A_1 = \begin{bmatrix} 2 & -1 \\ 0 & 2 \end{bmatrix} \cdot \begin{bmatrix} 3 & 1 \\ 1 & 2 \end{bmatrix} = \begin{bmatrix} 5 & 0 \\ 2 & 4 \end{bmatrix}\]
This is matrix multiplication. The product of two matrices gives you the matrix of the combined transformation.
Notice the order: \(A_1\) is applied first but appears on the right. \(A_2\) is applied second but appears on the left. This is because transformations act on the vector from the inside out: \(A_2(A_1 \mathbf{x}) = (A_2 \cdot A_1) \mathbf{x}\).
Dot Product Formula
Is there a fast way to compute matrix multiplication without drawing transformations? Yes, and you have already seen the building block: the dot product.
Look at the left matrix as rows and the right matrix as columns. Each entry in the result is the dot product of a row from the left matrix and a column from the right matrix:
\[\begin{bmatrix} 2 & -1 \\ 0 & 2 \end{bmatrix} \cdot \begin{bmatrix} 3 & 1 \\ 1 & 2 \end{bmatrix} = \begin{bmatrix} (2)(3)+(-1)(1) & (2)(1)+(-1)(2) \\ (0)(3)+(2)(1) & (0)(1)+(2)(2) \end{bmatrix} = \begin{bmatrix} 5 & 0 \\ 2 & 4 \end{bmatrix}\]
Row 1 dotted with column 1 gives the top-left entry. Row 1 dotted with column 2 gives the top-right entry. And so on.
Rectangular Matrices
Matrix multiplication also works when the matrices are not square. The only rule is that the number of columns of the left matrix must equal the number of rows of the right matrix.
For example, multiply a \(2 \times 3\) matrix by a \(3 \times 4\) matrix. The result is a \(2 \times 4\) matrix:
\[\underbrace{\begin{bmatrix} 3 & 1 & 4 \\ 2 & -1 & 2 \end{bmatrix}}_{2 \times 3} \cdot \underbrace{\begin{bmatrix} 3 & 0 & 5 & 1 \\ 1 & 5 & 2 & 3 \\ -2 & 1 & -1 & 0 \end{bmatrix}}_{3 \times 4} = \underbrace{\begin{bmatrix} 2 & 9 & 13 & 6 \\ 1 & -3 & 6 & -1 \end{bmatrix}}_{2 \times 4}\]
Let’s verify the bottom-left entry: row 2 of the left matrix dotted with column 1 of the right matrix: \((2)(3) + (-1)(1) + (2)(-2) = 6 - 1 - 4 = 1\). Correct.
Dimension Rules
The key takeaways for matrix multiplication:
\[\underbrace{A}_{m \times \mathbf{n}} \cdot \underbrace{B}_{\mathbf{n} \times p} = \underbrace{C}_{m \times p}\]
- The inner dimensions must match: the number of columns of \(A\) must equal the number of rows of \(B\) (both \(n\))
- The result takes its rows from \(A\) (\(m\) rows)
- The result takes its columns from \(B\) (\(p\) columns)
Otherwise, it works just like the \(2 \times 2\) examples: take the dot product of rows from the left matrix and columns from the right matrix to fill in each cell of the result.
Review Questions
1. Which of the following is the result of performing the multiplication \(M_1 \cdot M_2\)? Where \(M_1\) and \(M_2\) are given by:
\[M_1 = \begin{bmatrix} 2 & -1 \\ 3 & -3 \end{bmatrix}, \quad M_2 = \begin{bmatrix} 5 & -2 \\ 0 & 1 \end{bmatrix}\]
TipAnswer
\[M_1 \cdot M_2 = \begin{bmatrix} 2(5)+(-1)(0) & 2(-2)+(-1)(1) \\ 3(5)+(-3)(0) & 3(-2)+(-3)(1) \end{bmatrix} = \begin{bmatrix} 10 & -5 \\ 15 & -9 \end{bmatrix}\]
Identity Matrix
When you think of numbers and multiplication, the number 1 is special: multiplying any number by 1 gives you the same number you started with. The identity matrix plays the exact same role among matrices.
The identity matrix has ones on the diagonal and zeros everywhere else:
\[I = \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{bmatrix}\]
When you multiply any vector by the identity matrix, you get the same vector back:
\[I \begin{bmatrix} a \\ b \\ c \end{bmatrix} = \begin{bmatrix} 1 \cdot a + 0 \cdot b + 0 \cdot c \\ 0 \cdot a + 1 \cdot b + 0 \cdot c \\ 0 \cdot a + 0 \cdot b + 1 \cdot c \end{bmatrix} = \begin{bmatrix} a \\ b \\ c \end{bmatrix}\]
The same holds for matrix multiplication: \(I \cdot A = A\) and \(A \cdot I = A\) for any matrix \(A\).
As a linear transformation, the identity matrix sends every point to itself. The unit square stays the unit square. Nothing moves. That is why it is called the identity.
Inverse of a Matrix
When you think of numbers, the inverse of 2 is \(\frac{1}{2}\), because \(2 \times \frac{1}{2} = 1\). The inverse of \(-5\) is \(-\frac{1}{5}\), because \((-5) \times (-\frac{1}{5}) = 1\). In every case, a number times its inverse gives you 1.
The inverse of a matrix works the same way: it is the matrix that, when multiplied by the original, gives the identity matrix.
Transformation That Undoes
Recall the matrix \(A = \begin{bmatrix} 3 & 1 \\ 1 & 2 \end{bmatrix}\) that turns the unit square into a parallelogram. There exists some other transformation that turns that parallelogram back into the original square. The composition of the two is the identity: the plane ends up exactly where it started.

If the inverse matrix is \(A^{-1} = \begin{bmatrix} a & b \\ c & d \end{bmatrix}\), then by definition:
\[A \cdot A^{-1} = \begin{bmatrix} 3 & 1 \\ 1 & 2 \end{bmatrix} \cdot \begin{bmatrix} a & b \\ c & d \end{bmatrix} = \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}\]
Just like with numbers, we write the inverse as \(A^{-1}\) (the matrix raised to the power \(-1\)).
Finding the Inverse
How do you find \(a, b, c, d\)? By solving a system of linear equations. The matrix equation above gives four dot products, each producing one equation:
\[\begin{cases} 3a + c = 1 \\ 3b + d = 0 \\ a + 2c = 0 \\ b + 2d = 1 \end{cases}\]
Using the elimination methods from the earlier notes, you can solve this to get:
\[A^{-1} = \begin{bmatrix} \frac{2}{5} & -\frac{1}{5} \\ -\frac{1}{5} & \frac{3}{5} \end{bmatrix}\]
You can verify: \(A \cdot A^{-1} = I\).
When the Inverse Does Not Exist
Not every matrix has an inverse. Consider the matrix \(\begin{bmatrix} 1 & 2 \\ 2 & 4 \end{bmatrix}\). If you try to find its inverse, you set up the system:
\[\begin{cases} a + 2c = 1 \\ 2a + 4c = 0 \end{cases}\]
The first equation says \(a + 2c = 1\), so \(2a + 4c\) must be 2. But the second equation says \(2a + 4c = 0\). That is a contradiction. The inverse does not exist.
This should look familiar. The second row is twice the first row, so the matrix is singular. Singular matrices do not have inverses. As a transformation, a singular matrix collapses the plane onto a line (or a point), and you cannot undo that.
Review Questions
1. Find the inverse of the following matrix:
\[B = \begin{bmatrix} 5 & 2 \\ 1 & 4 \end{bmatrix}\]
TipAnswer
Set up \(B \cdot B^{-1} = I\):
\[\begin{cases} 5a + 2c = 1 \\ 5b + 2d = 0 \\ a + 4c = 0 \\ b + 4d = 1 \end{cases}\]
From equations 1 and 3: \(a + 4c = 0 \Rightarrow a = -4c\). Substituting into \(5(-4c) + 2c = 1\): \(-18c = 1\), so \(c = -\frac{1}{18}\) and \(a = \frac{4}{18} = \frac{2}{9}\).
From equations 2 and 4: \(b + 4d = 1 \Rightarrow b = 1 - 4d\). Substituting into \(5(1 - 4d) + 2d = 0\): \(5 - 18d = 0\), so \(d = \frac{5}{18}\) and \(b = 1 - \frac{20}{18} = -\frac{1}{9}\).
\[B^{-1} = \begin{bmatrix} \frac{2}{9} & -\frac{1}{9} \\ -\frac{1}{18} & \frac{5}{18} \end{bmatrix}\]
1. Find the inverse of the following matrix:
\[C = \begin{bmatrix} 5 & 2 \\ 1 & 2 \end{bmatrix}\]
TipAnswer
The determinant is \(5(2) - 2(1) = 8 \neq 0\), so the inverse exists. Using the formula: \(C^{-1} = \frac{1}{8}\begin{bmatrix} 2 & -2 \\ -1 & 5 \end{bmatrix} = \begin{bmatrix} \frac{1}{4} & -\frac{1}{4} \\ -\frac{1}{8} & \frac{5}{8} \end{bmatrix}\).
1. Find the inverse of the following matrix:
\[D = \begin{bmatrix} 1 & 1 \\ 2 & 2 \end{bmatrix}\]
TipAnswer
The determinant is \(1(2) - 1(2) = 0\). The second row is twice the first row, so the matrix is singular. Singular matrices do not have inverses. As a transformation, this matrix collapses the entire plane onto a line, and that cannot be undone.
1. When computing an inverse matrix via linear systems, what do the variables \(a\), \(b\), \(c\), and \(d\) represent?
TipAnswer
They are the unknown entries of the inverse matrix \(A^{-1} = \begin{bmatrix} a & b \\ c & d \end{bmatrix}\). You solve for them by setting up the equation \(A \cdot A^{-1} = I\) and expanding the matrix product into a system of linear equations (one equation per entry of the identity matrix).
Which Matrices Have an Inverse?
Matrices behave a lot like numbers. Some numbers have multiplicative inverses: the inverse of 5 is \(\frac{1}{5}\), the inverse of 8 is \(\frac{1}{8}\). But the number 0 has no inverse, because there is no number that when multiplied by 0 gives 1.
The same is true for matrices. The rule is something you have already learned:
- Non-singular matrices (linearly independent rows, full rank) always have an inverse. That is why they are also called invertible.
- Singular matrices (linearly dependent rows, less than full rank) never have an inverse. That is why they are called non-invertible.
The determinant gives you a quick test. Just like non-zero numbers have inverses and zero does not:
| Determinant | Matrix type | Inverse? |
|---|---|---|
| \(\neq 0\) | Non-singular | Invertible |
| \(= 0\) | Singular | Not invertible |
For example:
\[\det \begin{bmatrix} 3 & 1 \\ 1 & 2 \end{bmatrix} = 5 \neq 0 \quad \Rightarrow \quad \text{invertible}\]
\[\det \begin{bmatrix} 1 & 2 \\ 2 & 4 \end{bmatrix} = 0 \quad \Rightarrow \quad \text{not invertible}\]
A non-zero determinant means the matrix has an inverse. A zero determinant means it does not.
Application: A Simple Neural Network (Perceptron)
Neural networks, one of the most successful and powerful machine learning models, are based largely on matrices and matrix products. Each layer of a neural network applies a linear transformation \(A\mathbf{x}\) followed by a non-linear activation function. Let’s see a concrete example of how this works with a real problem.
A Spam Classifier
Imagine you have a spam dataset. You have identified two words that are quite deterministic for spam: “lottery” and “win”. These seem to appear more in spam emails, but their appearance alone does not guarantee that the email is spam. You count how many times each word appears in several emails and record whether each email is spam:
| Spam? | “lottery” | “win” |
|---|---|---|
| Yes | 1 | 1 |
| Yes | 2 | 1 |
| No | 0 | 0 |
| Yes | 0 | 2 |
| No | 0 | 1 |
| No | 1 | 0 |
| Yes | 2 | 2 |
| Yes | 2 | 0 |
| Yes | 1 | 2 |
The goal is to build a classifier: a little machine that tries to guess if an email is spam or not based on this table. The classifier works as follows:
- Assign a score to the word “lottery” and a score to the word “win”
- Calculate the score of an email by adding the word scores with repetition
- If the total score is bigger than some threshold, classify the email as spam
For example, if the score for “lottery” is 3 and the score for “win” is 2, then the sentence “Win, win the lottery!” gets a total score of \(3(1) + 2(2) = 7\) points (3 for one appearance of “lottery”, 2 for each of the two appearances of “win”).
The goal is to find the best possible scores and threshold so that the classifier’s predictions match the spam column as closely as possible. It turns out you can find values that classify every single email in the table correctly. The words “lottery” and “win” both get a score of 1, and the threshold is 1.5:
- Email 1: \(1(1) + 1(1) = 2 > 1.5\) → Spam ✓
- Email 2: \(1(2) + 1(1) = 3 > 1.5\) → Spam ✓
- Email 3: \(1(0) + 1(0) = 0 < 1.5\) → Not spam ✓
- Email 4: \(1(0) + 1(2) = 2 > 1.5\) → Spam ✓
- Email 5: \(1(0) + 1(1) = 1 < 1.5\) → Not spam ✓
- Email 6: \(1(1) + 1(0) = 1 < 1.5\) → Not spam ✓
- Email 7: \(1(2) + 1(2) = 4 > 1.5\) → Spam ✓
- Email 8: \(1(2) + 1(0) = 2 > 1.5\) → Spam ✓
- Email 9: \(1(1) + 1(2) = 3 > 1.5\) → Spam ✓
Perfect classification. The scores end up being the sums of the number of times each word appears, and when you check whether that sum exceeds the threshold of 1.5, the predictions match the actual spam labels exactly.
As a Matrix-Vector Product
Notice what just happened. The scores for each email are computed by taking the dot product of each row of the data matrix with the model vector:
\[\begin{bmatrix} 1 & 1 \\ 2 & 1 \\ 0 & 0 \\ 0 & 2 \\ 0 & 1 \\ 1 & 0 \\ 2 & 2 \\ 2 & 0 \\ 1 & 2 \end{bmatrix} \cdot \begin{bmatrix} 1 \\ 1 \end{bmatrix} = \begin{bmatrix} 2 \\ 3 \\ 0 \\ 2 \\ 1 \\ 1 \\ 4 \\ 2 \\ 3 \end{bmatrix}\]
Then you apply the threshold check to each entry: if the score is \(> 1.5\), predict spam. This check is the activation function. If you had many more words, you would simply have a much wider matrix on the left and a much longer model vector on the right, but the math works exactly the same way.
Geometric View
Plot the dataset with “lottery” on one axis and “win” on the other. The spam and non-spam emails separate cleanly:

The line \(x + y = 1.5\) separates spam from not spam. The more appearances of the words “lottery” and “win”, the higher the score and the more likely the email is spam. This is a linear classifier: a straight line (or hyperplane in higher dimensions) that divides the space into two regions.
Perceptron
This classifier is the simplest possible neural network: a perceptron (one layer, one neuron). It works as follows:
- Take the input vector \(\mathbf{x}\) (word counts)
- Compute the dot product \(\mathbf{w} \cdot \mathbf{x} + b\), where \(\mathbf{w}\) are the weights and \(b\) is the bias (which equals \(-\text{threshold} = -1.5\))
- Apply the activation function: output 1 (spam) if the result is \(\geq 0\), output 0 (not spam) otherwise
Including the bias in the matrix multiplication is a common trick. You add a column of ones to the data and append the bias to the weight vector:
\[\begin{bmatrix} 1 & 1 & 1 \\ 2 & 1 & 1 \\ 0 & 0 & 1 \\ 0 & 2 & 1 \\ 0 & 1 & 1 \\ 1 & 0 & 1 \\ 2 & 2 & 1 \\ 2 & 0 & 1 \\ 1 & 2 & 1 \end{bmatrix} \cdot \begin{bmatrix} 1 \\ 1 \\ -1.5 \end{bmatrix} = \begin{bmatrix} 0.5 \\ 1.5 \\ -1.5 \\ 0.5 \\ -0.5 \\ -0.5 \\ 2.5 \\ 0.5 \\ 1.5 \end{bmatrix}\]
Now instead of checking against a threshold, you just check if each entry is \(\geq 0\). Same classifier, cleaner formulation. Sometimes you will see classifiers written with the bias and sometimes with the threshold. For more complex neural networks, the bias formulation tends to be more common.
AND Operator
Here is a simpler example that uses the same idea. Consider the AND operator: it outputs “Yes” only when both inputs are 1.
| \(x\) | \(y\) | AND |
|---|---|---|
| 0 | 0 | No |
| 0 | 1 | No |
| 1 | 0 | No |
| 1 | 1 | Yes |
This is just a subset of the spam dataset with the same labels. The same perceptron with weights \([1, 1]\) and threshold \(1.5\) classifies it perfectly:
- \((0, 0)\): \(0 + 0 = 0 < 1.5\) → No ✓
- \((0, 1)\): \(0 + 1 = 1 < 1.5\) → No ✓
- \((1, 0)\): \(1 + 0 = 1 < 1.5\) → No ✓
- \((1, 1)\): \(1 + 1 = 2 > 1.5\) → Yes ✓
The same decision boundary \(x + y = 1.5\) separates the points. The AND operator can be modeled as a perceptron, a one-layer neural network. This is the foundation that more complex neural networks build on: matrix multiplication followed by an activation function, repeated layer after layer.
Lab 1: Visualizing Linear Transformations with NumPy
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import PolygonDefine a helper to plot the original and transformed unit square:
def plot_transform(A, title=''):
pts = np.array([[0, 0], [1, 0], [1, 1], [0, 1]])
pts_t = (A @ pts.T).T
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
for ax, p, color, label in [
(axes[0], pts, '#87CEEB', 'Original'),
(axes[1], pts_t, '#FFB347', 'Transformed')
]:
poly = Polygon(p, closed=True, fc=color, ec='gray', lw=2, alpha=0.5)
ax.add_patch(poly)
for pt in p:
ax.plot(*pt, 'o', color='gray', markersize=5, zorder=5)
ax.set_xlim(-2, 4)
ax.set_ylim(-2, 4)
ax.set_aspect('equal')
ax.grid(True, linestyle='--', alpha=0.4)
ax.axhline(0, color='black', linewidth=0.8)
ax.axvline(0, color='black', linewidth=0.8)
ax.set_title(label, fontsize=11, color='gray')
fig.suptitle(title, fontsize=13)
plt.tight_layout()
plt.show()The matrix from the example above:
A = np.array([[3, 1],
[1, 2]])
plot_transform(A, 'A = [[3, 1], [1, 2]]')
A rotation by 90 degrees:
theta = np.pi / 2
R = np.array([[np.cos(theta), -np.sin(theta)],
[np.sin(theta), np.cos(theta)]])
plot_transform(R, 'Rotation by 90 degrees')
A shear transformation:
S = np.array([[1, 1],
[0, 1]])
plot_transform(S, 'Shear: [[1, 1], [0, 1]]')
Composition: rotate 45 degrees, then scale by 2 horizontally:
theta = np.pi / 4
R45 = np.array([[np.cos(theta), -np.sin(theta)],
[np.sin(theta), np.cos(theta)]])
Scale = np.array([[2, 0],
[0, 1]])
# Scale applied after rotation: Scale @ R45
plot_transform(Scale @ R45, 'Scale(2,1) after Rotate(45 deg)')
Matrix-vector multiplication to verify the fruit store example:
A = np.array([[3, 1],
[1, 2]])
prices = np.array([1, 1])
print("Prices: apple=$1, banana=$1")
print("Day totals:", A @ prices)Prices: apple=$1, banana=$1
Day totals: [4 3]Matrix multiplication to verify the composition example:
A1 = np.array([[3, 1],
[1, 2]])
A2 = np.array([[2, -1],
[0, 2]])
print("A2 @ A1 =")
print(A2 @ A1)A2 @ A1 =
[[5 0]
[2 4]]Matrix Multiplication with NumPy
There are a few ways to perform matrix multiplication in Python. The most common are np.matmul() and the @ operator. Both give the same result:
A = np.array([[4, 9, 9], [9, 1, 6], [9, 2, 3]])
B = np.array([[2, 2], [5, 7], [4, 4]])
print("Matrix A (3x3):\n", A)
print("\nMatrix B (3x2):\n", B)Matrix A (3x3):
[[4 9 9]
[9 1 6]
[9 2 3]]
Matrix B (3x2):
[[2 2]
[5 7]
[4 4]]print("np.matmul(A, B):\n", np.matmul(A, B))
print("\nA @ B:\n", A @ B)np.matmul(A, B):
[[ 89 107]
[ 47 49]
[ 40 44]]
A @ B:
[[ 89 107]
[ 47 49]
[ 40 44]]The dimension rule applies: the number of columns of the first matrix must match the number of rows of the second. Reversing the order here fails because \(B\) is \(3 \times 2\) and \(A\) is \(3 \times 3\):
try:
B @ A
except ValueError as err:
print("Error:", err)Error: matmul: Input operand 1 has a mismatch in its core dimension 0, with gufunc signature (n?,k),(k,m?)->(n?,m?) (size 3 is different from 2)Broadcasting with Vectors
When you multiply two 1-D arrays with np.matmul(), NumPy automatically treats the first as a row vector and the second as a column vector, computing the dot product:
x = np.array([1, -2, -5])
y = np.array([4, 3, -1])
print("x shape:", x.shape)
print("np.matmul(x, y):", np.matmul(x, y))x shape: (3,)
np.matmul(x, y): 3This is convenient but can be surprising. If you explicitly reshape them as column vectors (\(3 \times 1\)), the multiplication fails because the dimensions no longer align:
try:
np.matmul(x.reshape((3, 1)), y.reshape((3, 1)))
except ValueError as err:
print("Error:", err)Error: matmul: Input operand 1 has a mismatch in its core dimension 0, with gufunc signature (n?,k),(k,m?)->(n?,m?) (size 3 is different from 1)np.dot() also works for matrix multiplication (it broadcasts the dot product across all rows and columns):
print("np.dot(A, B):\n", np.dot(A, B))np.dot(A, B):
[[ 89 107]
[ 47 49]
[ 40 44]]NumPy also broadcasts scalars. Subtracting a scalar from a matrix is not defined mathematically, but NumPy expands the scalar to match the matrix shape and performs element-wise subtraction:
print("A - 2:\n", A - 2)A - 2:
[[ 2 7 7]
[ 7 -1 4]
[ 7 0 1]]Rectangular matrix multiplication:
L = np.array([[3, 1, 4],
[2, -1, 2]])
R = np.array([[3, 0, 5, 1],
[1, 5, 2, 3],
[-2, 1, -1, 0]])
print(f"({L.shape[0]}x{L.shape[1]}) @ ({R.shape[0]}x{R.shape[1]}) = ({L.shape[0]}x{R.shape[1]})")
print(L @ R)(2x3) @ (3x4) = (2x4)
[[ 2 9 13 6]
[ 1 -3 6 -1]]Lab 2: Linear Transformations and Computer Graphics
import numpy as np
import cv2
import matplotlib.pyplot as pltTransformations as Functions
A transformation is a function from one vector space to another. Using the notation \(T: \mathbb{R}^2 \to \mathbb{R}^3\), you specify that \(T\) takes a 2D vector and produces a 3D vector. For example:
\[T\left(\begin{bmatrix} v_1 \\ v_2 \end{bmatrix}\right) = \begin{bmatrix} 3v_1 \\ 0 \\ -2v_2 \end{bmatrix}\]
def T(v):
w = np.zeros((3, 1))
w[0, 0] = 3 * v[0, 0]
w[2, 0] = -2 * v[1, 0]
return w
v = np.array([[3], [5]])
w = T(v)
print("Original vector:\n", v)
print("\nResult of the transformation:\n", w)Original vector:
[[3]
[5]]
Result of the transformation:
[[ 9.]
[ 0.]
[-10.]]Verifying Linearity
A transformation \(T\) is linear if \(T(k\mathbf{v}) = kT(\mathbf{v})\) and \(T(\mathbf{u} + \mathbf{v}) = T(\mathbf{u}) + T(\mathbf{v})\) for any scalar \(k\) and any vectors \(\mathbf{u}\), \(\mathbf{v}\):
u = np.array([[1], [-2]])
v = np.array([[2], [4]])
k = 7
print("T(k*v):\n", T(k * v))
print("k*T(v):\n", k * T(v))
print("\nT(u+v):\n", T(u + v))
print("T(u)+T(v):\n", T(u) + T(v))T(k*v):
[[ 42.]
[ 0.]
[-56.]]
k*T(v):
[[ 42.]
[ 0.]
[-56.]]
T(u+v):
[[ 9.]
[ 0.]
[-4.]]
T(u)+T(v):
[[ 9.]
[ 0.]
[-4.]]Both properties hold, confirming \(T\) is linear.
Finding the Matrix
Every linear transformation \(L: \mathbb{R}^m \to \mathbb{R}^n\) can be written as \(L(\mathbf{v}) = A\mathbf{v}\) for some \(n \times m\) matrix \(A\). For the transformation above:
\[L\left(\begin{bmatrix} v_1 \\ v_2 \end{bmatrix}\right) = \begin{bmatrix} 3v_1 \\ 0 \\ -2v_2 \end{bmatrix} = \begin{bmatrix} 3 & 0 \\ 0 & 0 \\ 0 & -2 \end{bmatrix} \begin{bmatrix} v_1 \\ v_2 \end{bmatrix}\]
def L(v):
A = np.array([[3, 0], [0, 0], [0, -2]])
print("Transformation matrix:\n", A)
w = A @ v
return w
v = np.array([[3], [5]])
w = L(v)
print("\nOriginal vector:\n", v)
print("\nResult of the transformation:\n", w)Transformation matrix:
[[ 3 0]
[ 0 0]
[ 0 -2]]
Original vector:
[[3]
[5]]
Result of the transformation:
[[ 9]
[ 0]
[-10]]The columns of \(A\) are the images of the standard basis vectors: \(A = [L(\mathbf{e}_1) \quad L(\mathbf{e}_2)]\).
Standard Transformations in a Plane
Define a helper to visualize how a transformation acts on the standard basis:
def plot_transformation(T, e1, e2):
color_original = "#129cab"
color_transformed = "#cc8933"
_, ax = plt.subplots(figsize=(6, 6))
ax.set_xlim(-3, 3)
ax.set_ylim(-3, 3)
ax.set_aspect('equal')
ax.grid(True, linestyle='--', alpha=0.4)
ax.axhline(0, color='black', linewidth=0.8)
ax.axvline(0, color='black', linewidth=0.8)
# Original basis vectors and parallelogram
ax.quiver(0, 0, e1[0, 0], e1[1, 0], angles='xy', scale_units='xy', scale=1,
color=color_original, width=0.02)
ax.quiver(0, 0, e2[0, 0], e2[1, 0], angles='xy', scale_units='xy', scale=1,
color=color_original, width=0.02)
ax.plot([0, e1[0, 0], e1[0, 0] + e2[0, 0], e2[0, 0], 0],
[0, e1[1, 0], e1[1, 0] + e2[1, 0], e2[1, 0], 0],
color=color_original, lw=1.5)
ax.text(e1[0, 0] + 0.1, e1[1, 0] + 0.1, '$e_1$', fontsize=12, color=color_original)
ax.text(e2[0, 0] + 0.1, e2[1, 0] + 0.1, '$e_2$', fontsize=12, color=color_original)
# Transformed basis vectors and parallelogram
e1_t = T(e1)
e2_t = T(e2)
ax.quiver(0, 0, e1_t[0, 0], e1_t[1, 0], angles='xy', scale_units='xy', scale=1,
color=color_transformed, width=0.02)
ax.quiver(0, 0, e2_t[0, 0], e2_t[1, 0], angles='xy', scale_units='xy', scale=1,
color=color_transformed, width=0.02)
ax.plot([0, e1_t[0, 0], e1_t[0, 0] + e2_t[0, 0], e2_t[0, 0], 0],
[0, e1_t[1, 0], e1_t[1, 0] + e2_t[1, 0], e2_t[1, 0], 0],
color=color_transformed, lw=1.5)
ax.text(e1_t[0, 0] + 0.1, e1_t[1, 0] + 0.1, '$T(e_1)$', fontsize=12, color=color_transformed)
ax.text(e2_t[0, 0] + 0.1, e2_t[1, 0] + 0.1, '$T(e_2)$', fontsize=12, color=color_transformed)
plt.show()Horizontal scaling (factor 2):
def T_hscaling(v):
A = np.array([[2, 0], [0, 1]])
return A @ v
e1 = np.array([[1], [0]])
e2 = np.array([[0], [1]])
plot_transformation(T_hscaling, e1, e2)
Reflection about the y-axis:
def T_reflection_yaxis(v):
A = np.array([[-1, 0], [0, 1]])
return A @ v
plot_transformation(T_reflection_yaxis, e1, e2)
Application: Computer Graphics
In computer graphics, complex shapes are built from simple ones through linear transformations (scaling, rotation, shearing). GPUs are designed specifically to handle matrix multiplications at high speed, making this approach efficient at scale.
Let’s apply transformations to a leaf shape stored as a set of 329,076 coordinate points. Each point is a vector \(\begin{bmatrix}x\\y\end{bmatrix}\) in the plane, and transforming the entire image is just one matrix multiplication.
%config InlineBackend.figure_formats = ['png']
leaf = np.loadtxt('../../media/image.txt')
fig, ax = plt.subplots(1, 1, figsize=(5, 6))
ax.scatter(leaf[0], leaf[1], s=0.01, color='#2E8B57')
ax.set_aspect('equal')
ax.set_title('Original leaf (329,076 points)', fontsize=12, color='gray')
ax.axis('off')
plt.tight_layout()
plt.show()
Rotate the leaf 90 degrees clockwise (\(\theta = -\pi/2\)):
theta = -np.pi / 2
R = np.array([[np.cos(theta), -np.sin(theta)],
[np.sin(theta), np.cos(theta)]])
leaf_rotated = R @ leaf
fig, ax = plt.subplots(1, 1, figsize=(6, 5))
ax.scatter(leaf_rotated[0], leaf_rotated[1], s=0.01, color='#2E8B57')
ax.set_aspect('equal')
ax.set_title('Rotated 90° clockwise', fontsize=12, color='gray')
ax.axis('off')
plt.tight_layout()
plt.show()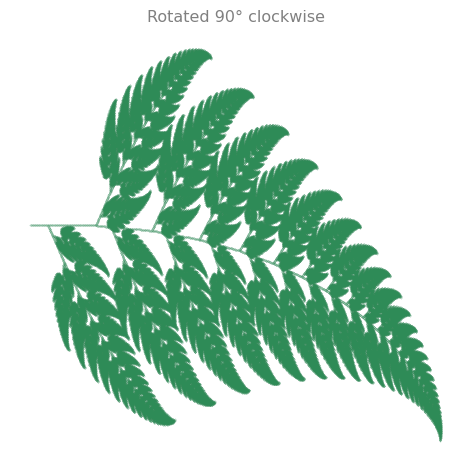
Applying a shear transformation to the rotated leaf:
M_shear = np.array([[1, 0.5], [0, 1]])
leaf_rotated_sheared = M_shear @ leaf_rotated
fig, ax = plt.subplots(1, 1, figsize=(6, 5))
ax.scatter(leaf_rotated_sheared[0], leaf_rotated_sheared[1], s=0.01, color='#2E8B57')
ax.set_aspect('equal')
ax.set_title('Rotated then sheared', fontsize=12, color='gray')
ax.axis('off')
plt.tight_layout()
plt.show()
What if you apply those two transformations in the opposite order? Run the following code to check:
leaf_sheared = M_shear @ leaf
leaf_sheared_rotated = R @ leaf_sheared
fig, ax = plt.subplots(1, 1, figsize=(6, 5))
ax.scatter(leaf_sheared_rotated[0], leaf_sheared_rotated[1], s=0.01, color='#2E8B57')
ax.set_aspect('equal')
ax.set_title('Sheared then rotated', fontsize=12, color='gray')
ax.axis('off')
plt.tight_layout()
plt.show()
Comparing the last two outputs, the results are clearly different. This is because linear transformations are defined as matrix multiplication, and applying two transformations in a row means computing \(B(Av) = (BA)v\). Since matrix multiplication is not commutative (\(BA \neq AB\) in general), the order matters.
Order Matters
Let’s verify this with the matrices directly:
M_rotation = np.array([[0, 1], [-1, 0]])
M_shear = np.array([[1, 0.5], [0, 1]])
print("Rotation then shear:\n", M_shear @ M_rotation)
print("\nShear then rotation:\n", M_rotation @ M_shear)Rotation then shear:
[[-0.5 1. ]
[-1. 0. ]]
Shear then rotation:
[[ 0. 1. ]
[-1. -0.5]]The two products are different, confirming that the order of transformations matters.